AS93
happy app
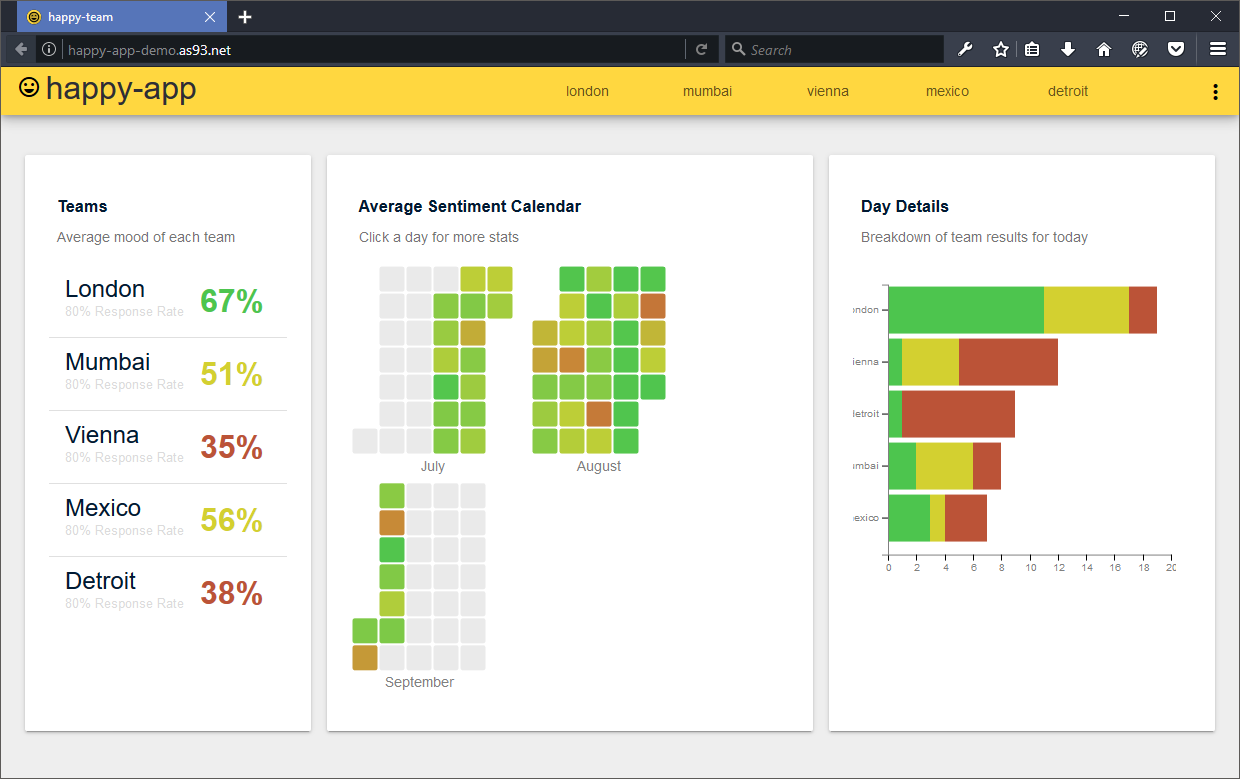
😃 Frictionless and anonymouse feedback system for agile teams

- License: MIT
- Stars: 15
- Author: Lissy93
- Language: Angular
Free & open source, forever. happy app is licensed under MIT © 2025 Alicia Sykes
15
2
9 MB
Jun, 2017
3 years ago
JavaScript